Kubernetes Architecture - Chapter 4 (Part 1)
It's getting interesting. We will explore Kubernetes architecture, the control plane, master and worker nodes, state management with etcd and finally Container Network Interface (CNI).
Learning Objectives
- Discuss the Kubernetes architecture.
- Explain the different components for master and worker nodes.
--------------------------
(part2) - Discuss about cluster state management with etcd.
- Review the Kubernetes network setup requirements.
Kubernetes Architecture

There are two main components to this diagram, there can be one or more master nodes, which are part of the control plane. And there are one or more worker nodes.
Master node components
We are introduced to the master node which provides a running environment for the control plane responsible for managing the state of a Kubernetes cluster. It is the brain behind all operations inside the cluster.
Losing the control plane may introduce downtime, so one can consider setting up multiple master nodes in High-Availability mode, with only one actively managing the cluster.
To persist the cluster's state, all cluster configuration data is saved to the etcd data-store, which we can also find in the Incubated Projects of the CNFC.
The kube-apiserver coordinates all administrative tasks on the master node.
It acts as the front end for the Kubernetes control plane. It is the only master plane component to talk to the etcd data-store, both to read from and to save Kubernetes cluster state information. It is possible to run several instances of the API server and balance traffic between those instances.
The role of the kube-scheduler is to assign new workload objects. During the scheduling process decisions are made based on current Kubernetes cluster state and new object's requirements. etcd sores resource usage data for each worker node in the cluster, which are received via the API server.
A scheduler will become extremely important and complex in a multi-node Kubernetes cluster, otherwise the scheduler's job will be quite simple.
The controller manager regulating the state of the Kubernetes cluster.
Controllers are watch-loops continuously running and comparing the cluster's desired state (provided by objects' configuration data) with its current state (obtained from etcd data store via the API server).
The kube-controller-manager is responsible to act when nodes become unavailable (Node controller), to ensure pod counts are as expected (Replication controller), to create endpoints (endpoints controller), service account and API access tokens(service account & token controllers). Each of these controllers are logically separate process but compiled into a single binary in a single process.
The cloud-controller-manager is responsible to interact with the underlying infrastructure of a cloud provider when nodes become unavailable(node controller), manage storage volumes, to manage load balancing(service controller) and routing (route controller).
Worker Node Components
A worker node provides a running environment for client applications. Though containerized microservices, these applications are encapsulated in Pods, controlled by the cluster control plane agents running on the master node.
A Pod is the smallest scheduling unit in Kubernetes. The scheduler assigns Pods to worker nodes. A Pod basically means that we share the context of a set of Linux namespaces, cgroups and potentially other facets of isolation.
The worker node consists of a Container Runtime, the kubelet, kube-proxy and addons for dns, dashboard, monitoring and logging.
Kubernetes is described as container orchestration engine, meaning it "only" orchestrates the container and doesn't handle them. Kubernetes requires a container runtime on the node where a Pod and its containers are to be scheduled.
Possible container runtimes are Docker, CRI-O, containerd, frakti. Docker is most frequently used, although it is a container platform which uses containerd as a container runtime.
The Node Agent, or kubelet, is an agent running on each node and communicates with the control plane components from the master node. The kubelet receives Pod definitions, interacts with the container runtime, monitors the health and resources of Pods running containers. Via the Container Runtime Interface shim the kubelet is able to have a clear abstraction layer between itself and the container runtime. There are also several shims available, the most common ones are dockershim, cri-containerd, CRI-O and frakti.
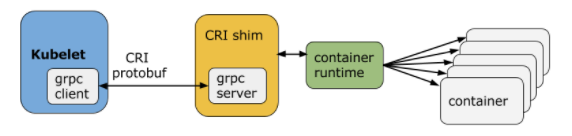
The CRI implements two services: ImageService and RuntimeService. The ImageService is responsible for all the image-related operations while the RuntimeService is responsible for all the Pod and container-related operations.
Any container runtime that implements the CRI can be used by Kubernetes to manage Pods, containers and container images.
You can learn more about it here.
The kube-proxy is the network agent which runs on each node responsible for dynamic updates and maintenance of all networking rules on the node.
The kube-proxy is responsible for TCP, UDP, and SCTP stream forwarding or round-robin forwarding across a set of Pod backends, and it implements forwarding rules defined by users through Service API objects.
We can see that Kubernetes is an abstraction layer to all the different implementations of container these days. While docker is the main platform used these days, I am eager to know which way container will go in the future. Is there even a need to serve them all? Why would one go with containerd, kata-containers or CRI-O. I guess time will tell, the orchestrator Kubernetes aims to reduce complexity in setting up these dynamic environments where they are needed, in a simplistic and well thought out way.
That's it friends, thanks for reading.